

在自然语言理解中,Word2Vec、EMLo 和 BERT 对各项语言理解任务的提升效果非常明显。而在语音识别和情感识别中,基于字符、音素等的编码识别则面临着很多的挑战。近日,李飞飞团队与斯坦福大学音乐与声学计算机研究中心联合提出了基于时间卷积网络 TCN 的句子编码新方法,通过模拟高级声学的架构,提升语音识别和情感识别效果。本文将对这项研究的细节进行概要介绍。
这项研究提出了口语句子嵌入这一全新方法,用于捕获声音和语言内容。虽然业界已有一些在字符、音素或者单词级别上操作的研究工作,但是该论文的方法通过在句子级别上建模语音来学习长距离依赖。作为一个音频语言多任务学习问题,研究中提出的编码器-解码器模型同时从音频中重建声音和自然语言特征。实验结果表明,在语音识别和情感识别任务上,口语句子嵌入效果优于音素和词级别的基准线。消融研究(Ablation studies)表明,该研究的嵌入方法可以更好地模拟高级声学的概念,同时保留语言内容。总的来说,该论文的工作说明了通用的、多模态句子嵌入对于口语理解的可行性。
介绍
在口头交流中,人类通常会等到出现一个完整的句子之后,再按顺序处理多个单词。然而,许多书面和口语语言系统隐含或者明确地依赖于单个字符和单词级别的表征。缺少句子级上下文会使理解包含连词、否定词和声调的句子变得困难。在这项工作中,我们调研了在口语处理领域的嵌入,并提出了口语句子嵌入,能够在单个潜码中对声学和语言内容进行建模。
机器表征单词可以追溯到 ASCII 码。one-hot 表征使用一个混合哑变量或者指示变量编码每个字符。虽然这个慢慢地被推广到单词级别,但是大量的语言词汇使其变得非常困难。 学习或者分布的词向量表征替换了 one-hot 编码。这些词向量能够捕获语义信息,包括来自相邻词的上下文。即使在今天,社区仍在继续构建更好的上下文嵌入,如:ELMo、ULMFit、BERT。语音、音素和字素嵌入如 Speech2Vec 和 Char2Wav 也被提出用于语音,遵循自然语言理解的技巧。
虽然字级嵌入很有希望,但是它们通常由于几个原因,不足以完成与语音相关的任务。
首先,单词和音素嵌入捕获的是一个狭窄的时间上下文,通常最多几百毫秒。因此,这些嵌入无法捕获长距离依赖,而这是高级推理(如段落或者歌曲级别理解)所需要的。几乎所有的语音识别系统都将注意力集中在局部上下文(如字母、单词和音素)的正确性上,而不是整体语义上。
其次,对于语音识别,经常使用外部语言模型来纠正字符和单词级别的预测。这需要添加复杂的多重假设生成方法。
句子级别嵌入比单词和字符级别嵌入更有优势。句子级别嵌入可以捕获跨单词的潜在因子。这对于更高级别的音频任务(如情感识别、韵律建模和音乐风格分析)非常有用。此外,大多数外部语言模型都在句子级别运作。通过一个句子级别的嵌入,嵌入可以在较长的上下文窗口大小下捕获声音和语音内容,从而通过学习时间结构完全减轻对外部语言模型的需要。
在这项工作中,我们的贡献包含两个方面。首先,我们建议通过学习口语句子的嵌入,从音素、字符和单词级的表征转移到句子级的理解。其次,我们设计这种嵌入来捕获语言和声学内容,以便学习可适用于各种语音和语言任务的潜在编码。在消融研究中,我们验证了嵌入的质量,并且评估了句子级别嵌入在语音识别和情绪分类中的一般性。我们相信这项工作将激励今后在语音处理、语义理解和多模态迁移学习方面的工作。
方法
在本节中,我们会讨论(1)如何使用时间卷积网络(temporal convolutional network)处理长序列;(2)如何在多任务学习框架下学习语言内容。
2.1 时间卷积网络(TCN)
我们的目标是学习一个口语句子嵌入,这可以用于各个语音任务。循环模型通常是序列建模任务的默认起点。对于大多数应用程序,最好的方法通常是从循环模型开始,在机器翻译、自动语音识别和语言合成任务中更是如此。
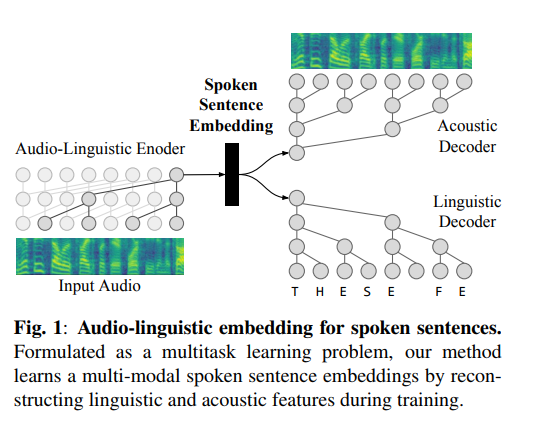
然而,众所周知,循环模型如循环神经网络(RNN)很难训练。多年来,机器学习研究人员一直试图通过引进新颖的训练策略和架构让训练 RNN 变得容易。在论文”An empirical evaluation of generic convolutional and recurrent networks for sequence modeling“ 中,作者表明在没有训练复杂性下,卷积网络优于循环网络。此外,它可以更好地捕获此类任务所需的长距离依赖。受这些发现的启发,在这项工作中,我们选择卷积序列模型(Figure 1)。类似于 WaveNet,我们使用了时间卷积网络(TCN)。虽然我们在这项工作中使用时间卷积网络(TCN),但是任何因果模型都足够(比如 Transformer)。
因果卷积(Causal Convolutions)
首先,我们介绍一些符号标识。
序列建模任务定义如下:给一个长度为 T 的输入序列,x=x1,…,xT,其中每个 x(t)是时间步长 t 的观测值。假设我们希望在每个时间步上进行一个 y(t)预测,然后我们有 y=y1,…yT。因果约束表明,在预测 y(t)时,它应该只依赖于过去的观察值 x(<t),而不是未来的观测值。例如,双向的 RNN 并不满足此约束。
空洞卷积(Dilated Convolutions)
标准的卷积有一个固定尺寸的滤波器(filter),因此具有固定的时间理解。如果我们的目标是学习句子嵌入,我们需要能够建模更长时间窗口的过滤器,理想的情况是对整个句子建模。在 WaveNet 研究等工作之后,我们利用空洞卷积在 TCN 的不同层,感知一个比较大的时间上下文窗口。对于输入序列 x=x1,…,xT ∈R(T)长度为 T 和滤波器(filter)f:{0,…,k-1}→ R ,filter 的大小为 k,在序列的元素 s 上的空洞卷积操作运算 F 为:
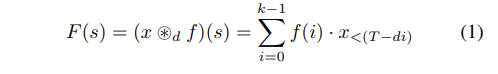
其中,d 是空洞因子,

表示卷积操作。当 d=1 时,空洞卷积退化为标准卷积。图 1 显示了空洞因子(dilation factor)d=2,kernel 大小为 2 的时间卷积网络(TCN)。TCN 允许我们使用单个编码器对整个句子进行建模,通常具有数百到数千个时间步长。该编码器产生固定大小的嵌入向量,其包含来自输入音频和语言信息。我们将在下一节中详细解释这个过程。
2.2 声学和语言学的多任务学习
在前一节中,我们解释了如何使用 TCN 将可变长度的口语句子转换为单个固定长度的向量。我们现在讨论如何使用多任务学习将声音和语言内容编码到这个向量中。我们以一个特定的预测问题(例如,语音识别、情绪识别、说话者验证)作为任务。多任务学习尝试训练一个模型以同时执行多个任务。最简单的方法是组合特定任务的损失函数
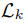
到单个的 loss 标准
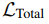
=
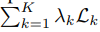
,其中
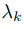
为任意任务加权系数,k 表示任务索引。我们使用硬参数共享作为 TCN 编码器为声学和语言解码器共享。声学目标是原始的梅尔声谱输入,而语言目标是文本转录。
实验
我们的实验程序由两部分组成。首先,我们从 TIMIT 和 LibriSpeech 中学习单个音素、单词和句子嵌入。这些包括以前发布的基线和我们提出的口语句子嵌入。其次,我们在自动语音识别和情感识别上评估这些嵌入。
3.1 配置
数据集
我们在 LibriSpeech 数据集上训练我们的模型。此训练集包括 460 个小时的 16kHz 的英语演讲。对于语音识别,我们使用 LibriSpeech 和 TIMIT 数据集并在测试集上报告了结果。对于情感识别,我们使用情感语言数据库(Ryerson Audio-Visual)和歌曲(RAVDESS)数据集,它包含 24 个演讲者展示 7 种情绪。
由于没有官方的训练和测试集的分割,因此使用四折叠交叉验证(75%的训练,25%的测试)报告结果。所有方法中,使用的输入表征都是具有 80 个梅尔滤波器的对数梅尔声谱,其中音频以 16kHz 采样。
评估指标
语音识别性能使用音素(PER)和字错误率(WER)来评估。而情感识别是一个多层次的分类问题,其评价方法包括 accuracy、precision 和 recall。
3.2 基线
我们现在讨论我们的方案和基线的结果。
要计算句子级嵌入,我们必须确定(1)使用那种中间嵌入;(2)如何将它们融合成单个句子级嵌入。
中间嵌入
我们选择两个基线嵌入作为学习中间语音的表征。之所以选择嵌入是因为它们易于使用并且适用于语言任务。
1.Speech2Vec
Speech2Vec 方法学习口语的嵌入。虽然该方法需要单词对齐(和分段等),但是,可以以无监督的方式训练。同一个单词的不同发音有不同的嵌入。这与 Word2Vec 相同,但是适用于口语。
2.Phoneme2Vec
它与 Speech2Vec 相同,但是适用于音素。音素的每个发音都被编码为一个嵌入。这个对于细粒度任务很有用。
我们在 LibriSpeech 数据集上训练 Speech2Vec 和 Phoneme2Vec ,使用高斯混合模型计算单词和音素对齐。
融合方法
对于这些基线,一旦我们有每个单词或者音素的嵌入,我们必须将它们组合成一个句子嵌入,我们评估了两种融合方法。
1.Uniform Average
通过计算每个单词或者音素位置的中间嵌入的元素和,并除以句子中的单词数,将中间嵌入转换为句子嵌入。这就是 uniform average。
2.深度平均网络(DAN)
首先,计算中间嵌入的平均值,然后将平均值向量输入深度神经网络生成最终的句子嵌入。该神经网络使用编码器进行训练,使用第 2.2 节中相同的多任务损失目标函数。
对于 DAN,深度神经网络将简单平均值转换为句子嵌入。该神经网络是较大的 encoder-decoder 模型的编码器组件,它是离线训练完成的。该 encoder-decoder 模型是一个多任务学习问题,有两个解码器:一个用于声学,一个用于语义(或语言)内容。
结果
4.1 语音处理任务
在数据集 LibriSpeech 上训练了我们的模型,我们使用编码器生成口语句子嵌入在 TIMIT 和 RAVDESS 上。编码器的权重在训练后是固定的,仅用于抽取嵌入。我们现在有了针对 TIMIT 和 RAVDESS 的句子嵌入,这样可以训练一个简单的用于自动语音识别的 RNN 解码器和一个用于情绪识别的 SVM 分类器。表 1 显示了两个任务的结果。
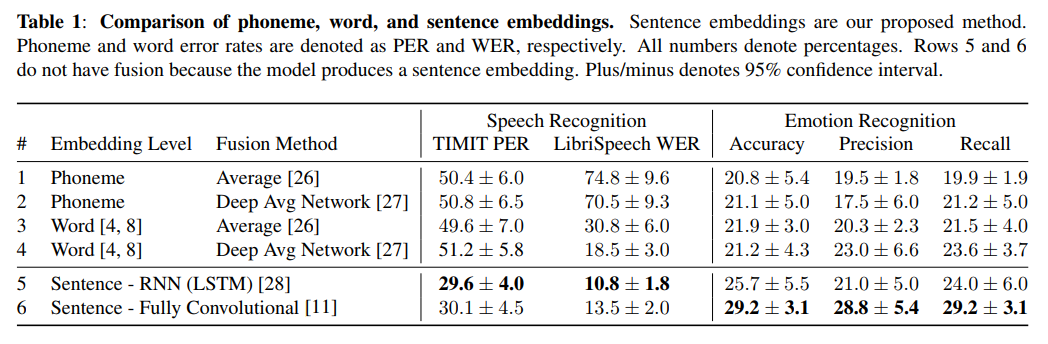
句子级嵌入在这两个任务上表现均优于音素和单词嵌入。这对于 RNN 和我们的完全卷积 TCN 模型都是如此。与我们方法学习的嵌入相比,音素级嵌入在语音识别方面表现不佳(WER 超过 70%)。与融合方法相比,深度平均网络(DAN)并没有显著超过 uniform average 水平。均匀平均向量(即输入)已经是信息瓶颈。
4.2 消融研究
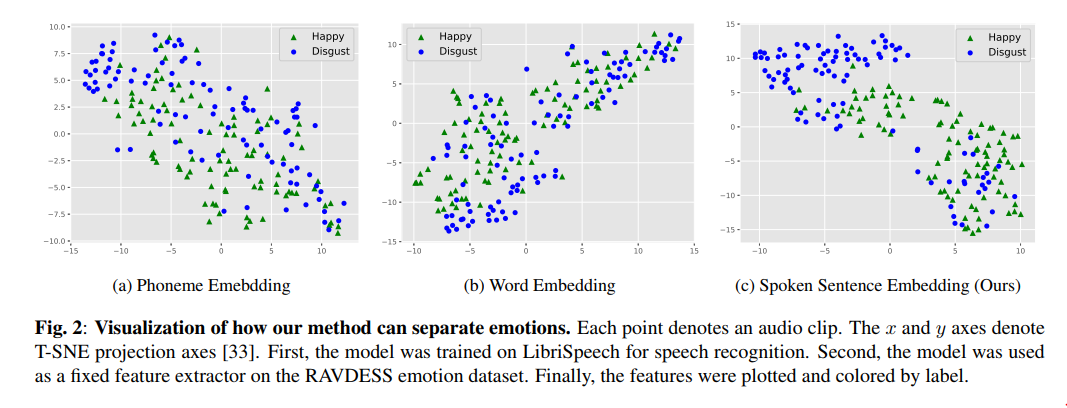
嵌入空间的可视化
对于这个实验,我们采用了预训练的口语句码编码器,在 LibriSpeech 上训练,并为每个 RAVDESS 音频片段提取句子嵌入。然后我们在图 2 中可视化了不同情绪的嵌入。请注意,我们的模型从未见过来自 Ravdes 数据集的训练样本。在没有进行情绪识别训练的情况下,我们的句子嵌入仍然可以聚集情绪。
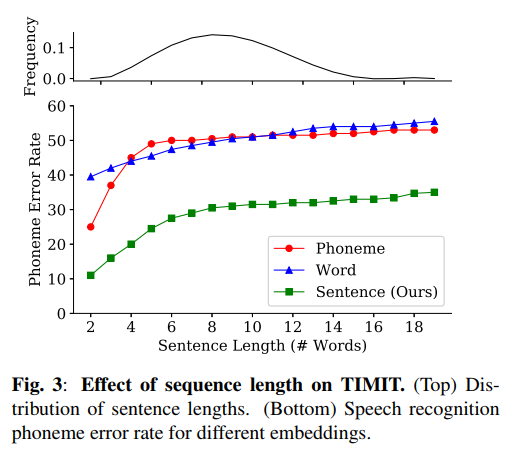
序列长度与性能
图 3 显示了序列长度对语音识别性能的影响。一般来说,当句子变长时,简单嵌入的性能表现为较低的性能。我们的方法也证实了这种模式,因为较长的句子有更多的内容拟合固定大小的嵌入。这个问题可以通过可变长度嵌入来解决,其长度随着句子的长度线性增长。
讨论
相关工作
句子表征的概念在自然语言和口语处理界都已经得到了探索。在自然语言方面,已有研究人员提出了跳跃思维(skip-thought)向量和复述句子(paraphrastic sentence)嵌入。在语音方面,已经提出了全句最大熵模型、整句模型和时间延迟网络。与我们的工作密切相关的是 Speech2Vec [8],它在我们的实验中使用。虽然 Speech2Vec 是为单词设计的,但它也可以扩展为句子。与我们的工作最相似的是来自自然语言处理的通用句子编码器(USE)。他们提出了两个句子编码器。每个编码器接受一个句子并产生一个向量。第一个编码器基于 Attention[24]。第二个编码器对单个字嵌入进行平均,并将结果输入神经网络[27]。与 USE 相比,我们的方法不对中间词级特征进行建模,而是直接学习句子嵌入。我们相信这可以更好地模拟长距离的上下文,因为单词间的关系不会通过求平均值而丢失。
结论和未来的工作
在这项工作中,我们提出了一种学习口语句子嵌入的方法,该方法可以捕获声学和语言内容。我们将该问题表述为一个多任务学习问题,以重建声学和语言信息。我们的结果表明,我们的口语句子嵌入可用于情感识别和语音识别。未来的工作可以专注于学习口语的通用嵌入。
自然语言方面的工作很有前景,其中语音和音频可以提供额外的维度。与文本的文档级嵌入类似,进一步的音频研究对于全长歌曲和多句录音可以探索更大的时间上下文大小。总的来说,我们的工作说明了通用的、多模态的句子嵌入对于口语理解的可行性。
论文原文链接:
https://arxiv.org/pdf/1902.07817.pdf
更多内容,请关注 AI 前线

公众号推荐:
2024 年 1 月,InfoQ 研究中心重磅发布《大语言模型综合能力测评报告 2024》,揭示了 10 个大模型在语义理解、文学创作、知识问答等领域的卓越表现。ChatGPT-4、文心一言等领先模型在编程、逻辑推理等方面展现出惊人的进步,预示着大模型将在 2024 年迎来更广泛的应用和创新。关注公众号「AI 前线」,回复「大模型报告」免费获取电子版研究报告。


暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论