

现阶段最好的神经网络结构中,规范化(normalization)是一项重要技术。尽管规范化有利于网络训练的原因仍不清楚,但它已经被广泛的应用于提高模型的泛化能力、稳定训练过程、以及加速模型收敛,同时规范化也使得使用更高的学习率训练模型成为了可能。
近日,来自 MIT、谷歌大脑、斯坦福的三名研究人员提出了一项具有挑战性的工作(这项工作在 Facebook 工作期间完成),他们认为规范化的好处并不是唯一的。论文《Fixup Initialization: Residual Learning Without Normalization》中提出了一种固定更新初始化(fixed-update initialization,Fixup),该论文已被 ICLR2019 接收。我们对该方法做了简要介绍,本文是 AI 前线第 70 篇论文导读。
背 景
在人工智能应用发展火热的今天,创新的网络模型及其训练技巧成为了人工智能发展的核心技术。例如在 2016 年何凯明及其团队提出 ResNet 的残差学习结构后,大部分 SOTA 的识别系统都是基于这种在卷积网络与加性残差连接堆叠的结构上添加一些规范化机制而设计的。除了图像分类,多种类的规范化技术在很多其他领域,如机器翻译、生成模型等方面都扮演着重要的角色。
对于规范化技术能产生上述好处的原因,学术界目前还没有达成一种共识。这篇论文对以下这些方面进行了研究:
在不使用规范化的情况下,深度残差网络能否可靠地训练?
在不使用规范化的情况下,深度残差网络能否使用相同的学习率进行训练、能否以相同的速度收敛以及能够获得一样好的泛化能力,或者更好?
令人惊讶的是,研究人员发现对于上述的两个问题,回答是肯定的。同时,这篇论文也对以下几个问题进行了讨论(后文均使用第一人称编译):
为什么规范化有助于训练过程。在残差网络的初始化过程中,我们对一种低边界的梯度范数进行了研究,这可以很好的解释为什么使用标准初始化、规范化技术对于深度残差网络在大学习率的情况下是必要的。
在不使用规范化的情况下进行训练。我们提出了 Fixup 技术——一种通过修改网络的结构,对残差分支的标准初始化进行放缩的方法。Fixup 在不使用规范化对极深的残差网络训练时,可以使用最大的学习率。
图像分类。我们使用 Fixup 代替了批规范化过程,在图像分类的基准数据库 CIFAR-10(Wide-ResNet)与 ImageNet(ResNet)上进行了验证。实验结果表明,在使用了适当的正则化后,使用 Fixup 的方法训练出的网络可以与使用规范化的方法训练的网络达到相同的效果。
机器翻译。我们使用 Fixup 替代了规范化层,在机器翻译的基准数据库 IWSLT 和 WMT 使用 Transformer(一种发表于 2017 年 NeurIPS 的目前最好的机器翻译算法 )模型进行了训练。发现该方法可以超过基准线并在相同的框架下取得的目前最好的结果。
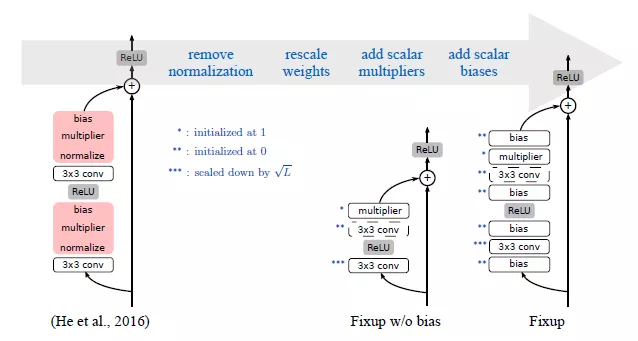
图 1:左:ResNet 标准残差块,红色表示批归一化层。中:一种简单的网络块,在堆叠时可以保持稳定。右:Fixup 结构,通过添加偏置更好地提升网络稳定性。
使用标准初始化的 ResNet 会导致梯度爆炸
标准初始化方法是为了初始化网络参数,防止发生梯度消失或梯度爆炸而提出的。然而,在不使用如 BatchNorm 等一些规范化的方法时,标准初始化并不能很好的解决残差连接中梯度爆炸的问题。针对该问题,Balduzzi 提出了一种 ReLU 网络,我们使用正定同质激活函数将 ReLU 网络的思想泛化到残差网络。不使用规范化层时,原始的 ResNet 中每个残差块的激活函数可以表达为:
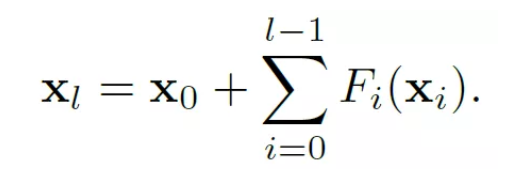
为了便于分析,我们分析使用了正定同质函数,首先介绍两个定义:

p.h.函数的例子在神经网络中是大量存在的。包括很多无偏的线性操作,例如全连接层、卷积层、池化层、串联层和 dropout 等,当然也包括 ReLU 这种非线性函数。此外,我们还引入了以下两个命题:

猜想 1 一个使用交叉熵损失的分类网络 f 可以看成是一个若干个网络块组成的集合,其中每个网络块都是一个 p.h.函数
猜想 2 FC 层的权重是从零均值对称分布中独立同分布采样得到的。
在一个使用了 ReLU 函数的残差网络中,如果我们移除了所有的规范化层,根据这些猜想可得到所有的偏置都被初始化为 0。
我们的结论可以总结为如下两条,证明过程在论文的附件中:

在图 2 中,我们提供了不使用规范化时 ResNet 中的三种 p.h.集合的例子。基于理论 2,如果未归一化概率值 z 在初始化的时候被放大了,这三个例子都有可能会遭遇梯度爆炸问题。而在 ResNet 中,如果不使用规范化,而使用传统方法初始化参数,上述情况是很有可能出现的。这就是我们提出一种新的初始化方法的动机。
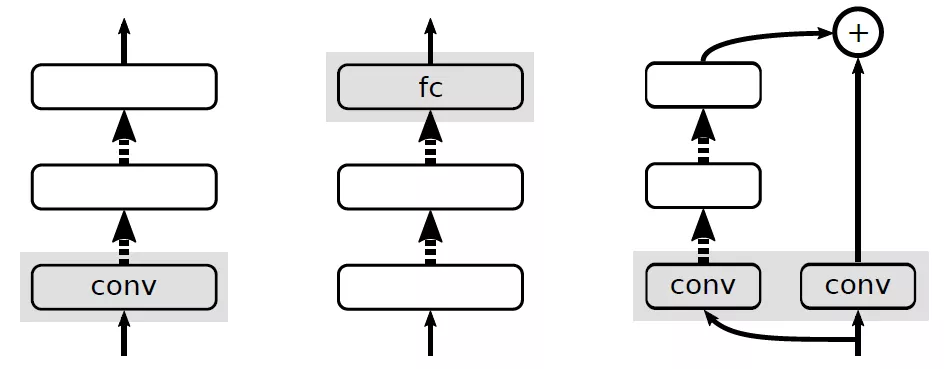
图 2:ResNet 中不使用规划范时 p.h.集的例子。(1)最大池化前的第一个卷积层;(2)softmax 层之前的全连接层;(3)主干网络中的空间降采样层和与其相对应的残差分支中的卷积层。
Fixup:在 SGD 的每一步更新残差网络
在这一部分,我们提出了一种由上至下的新的初始化方法。通过对标准初始化简单地放缩,可以保证在合适的范围更新网络函数。首先,我们假设学习率η并设定我们的目标:

从另一个角度讲,我们的目标是设计一种初始化方法,从而使 SGD 可以不依赖深度且以正确的比例对网络函数进行更新。
我们将捷径(Shortcut)定义为残差网络中从输入到输出的最短路径。捷径是一种典型的可训练的浅层网络。假设使用标准方法对捷径进行初始化,我们来分析一下残差分支的初始化情况。
残差分支同步更新网络。
最初,我们发现 SGD 在更新每个残差分支的时,会在高度相关的方向上改变网络的输出。这意味着,如果一个残差网络含有 L 个残差分支,那么每个残差分支在一次迭代中,应当对网络的输出平均改变Θ(η/L)从而达到对整个网路输出改变为Θ(η)。
对于标量分支的研究。

最终我们可以得到,当且仅当满足以下条件时:
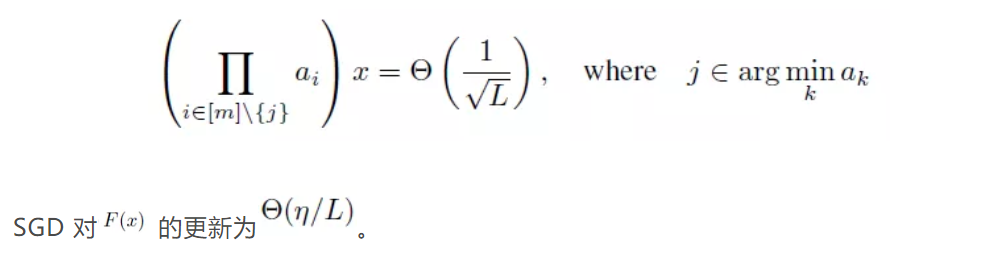

偏置和乘法器的影响。
通过对残差分支中权重的放缩,一个残差网络在 SGD 的每一步更新值为Θ(η),到这里我们的目标已经达成了。然而,为了使训练性能与使用规范化时相匹配,我们还需要考虑偏置和乘法器的情况。
在全连接层和卷积层使用偏置是一种很通用的方法。在规范化方法中,偏置和缩放参数被用来重建特征经过规范化操作后的表征能力。因为权重层与激活层的输入/输出均值可能不同,因此在不使用规范化的残差网络中插入偏置项同样可以有助于训练网络。我们发现在每个权重层和非线性激活层前仅插入一个标量偏置可以显著地提高训练性能。
乘法器会对残差分支的输出进行放缩,这与批规范化中的放缩参数功能类似(批规范化中两个重要参数为:scale 和 shift,即放缩与滑动)。我们发现,在每个残差分支中插入一个标量乘法器可以模仿使用规范化的网络中权重模值动态变化的过程。最终,我们得到了训练不使用规范化方法的残差网络的完整方法:
Fixup 初始化

实 验
我们在 CIFAR-10 数据库上测试了第一轮迭代(即数据库中所有图像通过模型一次)结束后模型的测试准确率,发现对于多种深度的卷积神经网络,在学习率相同的情况下 Fixup 可以达到与 BatchNorm 相同的效果。实验结果如下图所示:
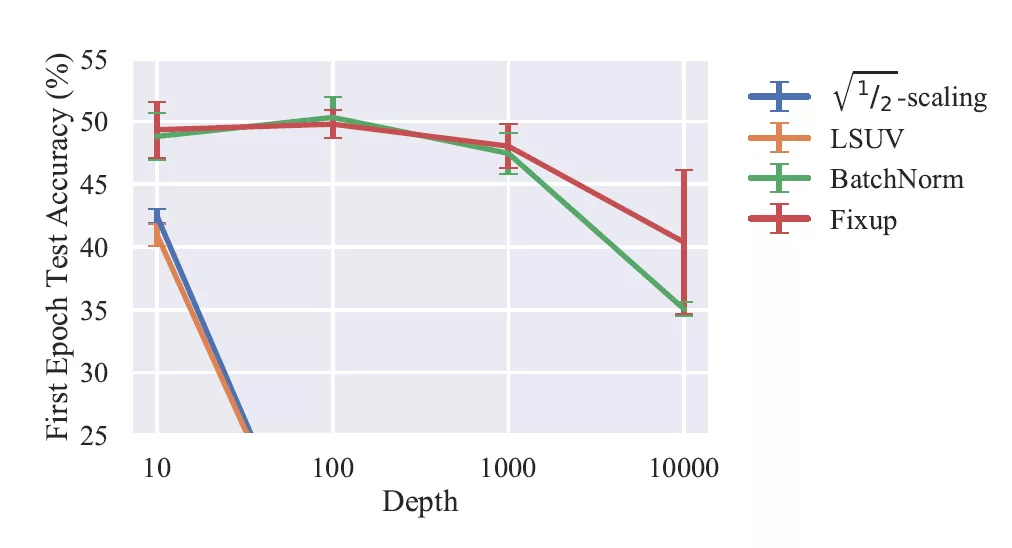
图 1 CIFAR-10 数据库上各种方法的训练结果比较,值越大表示结果越好。
此外,我们还对比了使用 Fixup 训练不同深度的 ResNet 和其他方法在 ImageNet 数据库上的结果,实验结果如下表所示:
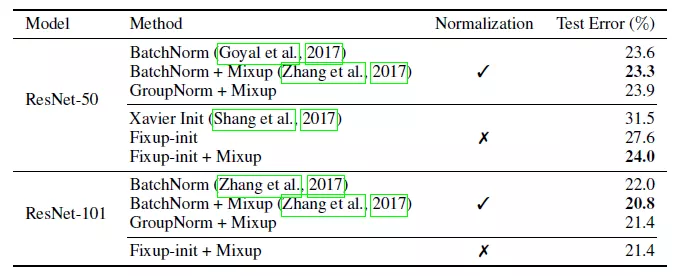
可以看出 Fixup 与组规范化方法的性能不相上下,该实验中通过交叉验证得到了三种方法的最优偏置标量,对于批规范化、组规范化和 Fixup 分别为 0.2,0.1 和 0.7。
此外,在机器翻译的 SOTA 方法中我们同样使用 Fixup 代替规范化层进行了实验。我们惊奇地发现,当使用 Fixup 代替规范化层可以更好地防止模型过拟合,我们认为这要归功于 dropout 操作的正则化。在两个数据库上,使用 Fixup 都取得了目前最好的结果,实验结果如下表:
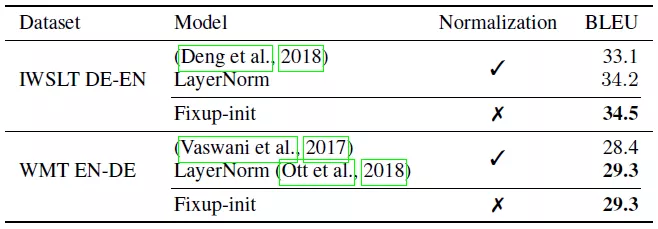
结 论
Fixup 通过对标准初始化进行适当的放缩来解决训练过程中梯度爆炸和梯度消失的问题。在不使用规范化的情况下,使用 Fixup 训练的残差网络可以达到与使用规范化训练时相同的稳定性,甚至在网络层数达到了 10000 层时也可以不相上下。此外,在使用了合适正则化方法的情况下,通过 Fixup 训练的不使用规范化的残差网络在图像分类和机器翻译上达到了目前最好的水平。在理论和应用两方面,这篇工作都给出了一种新的尝试。在理论层面,去除规范化有利于更简便地分析残差网络。在应用层面,Fixup 对于发展正则化方法提供了可能,比如结合 ZeroInit 等。
论文链接:https://arxiv.org/pdf/1901.09321.pdf

公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论