

这个简短的教程将介绍关于 JAX 的基础知识。JAX 是一个 Python 库,它通过函数转换来增强 numpy 和 Python 代码,使运行机器学习程序中常见的操作轻而易举。具体来说,它会使得编写标准 Python / numpy 代码变得简单,并且能够立即执行
通过 autograd 的后继计算函数的导数
及时编译函数,通过 XLA 在加速器上高效运行
自动矢量化函数,并执行处理“批量”数据等
在本教程中,我们将通过演示它在 AGI 的一个核心问题:使用神经网络学习异或(XOR)函数,依次介绍这些转换。
注意:此博客文章在此处提供交互式 Jupyter notebook:https://github.com/craffel/jax-tutorial
1 JAX 只是 numpy(大多数情况下)
从本质上讲,你可以将 JAX 视为使用执行上述转换所需的机器来增强 numpy。JAX 增强的 numpy 为 jax.numpy。除了少数例外,可以认为 jax.numpy 与 numpy 可直接互换。作为一般规则,当你计划使用 JAX 的任何转换(如计算渐变或即时编译代码),或希望代码在加速器上运行时,都应该使用 jax.numpy。当 jax.numpy 不支持你的计算时,用 numpy 就行了。
2 背景
如前所述,我们将使用小型神经网络学习 XOR 功能。 XOR 函数将两个二进制数作为输入并输出二进制数,如下图所示:
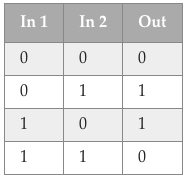
我们将使用具有 3 个神经元和双曲正切非线性的单个隐藏层的神经网络,通过随机梯度下降训练交叉熵损失。然后实现此模型和损失函数。请注意,代码与你在标准 numpy 中编写的完全一样。
如上所述,有些地方我们想要使用标准 numpy 而不是 jax.numpy。比如参数初始化。我们想在训练网络之前随机初始化参数,这不是我们需要衍生或编译的操作。JAX 使用自己的 jax.random 库而不是 numpy.random,为不同转换的复现性(种子)提供了更好的支持。由于我们不需要以任何方式转换参数的初始化,因此最简单的方法就是在这里使用标准
的 numpy.random 而不是 jax.random。
3 jax.grad
我们将使用的第一个转换是 jax.grad。jax.grad 接受一个函数并返回一个新函数,该函数计算原始函数的渐变。默认情况下,相对于第一个参数进行渐变;这可以通过 jgn.grad 的 argnums 参数来控制。要使用梯度下降,我们希望能够根据神经网络的参数计算损失函数的梯度。为此,使用 jax.grad(loss)就可以,它将提供一个可以调用以获得这些渐变的函数。

4 jax.jit
虽然我们精心编写的 numpy 代码运行起来效果还行,但对于现代机器学习来说,我们希望这些代码运行得尽可能快。这一般通过在 GPU 或 TPU 等不同的“加速器”上运行代码来实现。JAX 提供了一个 JIT(即时)编译器,它采用标准的 Python / numpy 函数,经编译可以在加速器上高效运行。编译函数还可以避免 Python 解释器的开销,这决定了你是否使用加速器。总的来说,jax.jit 可以显著加速代码运行,且基本上没有编码开销,你需要做的就是让 JAX 为你编译函数。使用 jax.jit 时,即使是微小的神经网络也可以实现相当惊人的加速度:
10 loops, best of 3: 13.1 ms per loop
1000 loops, best of 3: 862 µs per loop
请注意,JAX 允许我们将变换链接在一起。首先,我们使用 jax.grad 获取了丢失的梯度,然后使用 jax.jit 立即进行编译。这是使 JAX 更强大的一个因素——除了链接 jax.jit 和 jax.grad 之外,我们还可以多次应用 jax.grad 以获得更高阶的导数等。为了确保训练神经网络经过编译后仍然有效,我们再次对它进行训练。请注意,训练代码没有任何变化。

5 jax.vmap
精明的读者可能已经注意到,我们一直在一个例子上训练我们的神经网络。这是“真正的”随机梯度下降;在实践中,当训练现代机器学习模型时,我们执行“小批量”梯度下降,在梯度下降的每个步骤中,我们对一小批示例中的损失梯度求平均值。JAX 提供了 jax.vmap,这是一个自动“矢量化”函数的转换。这意味着它允许你在输入的某个轴上并行计算函数的输出。对我们来说,这意味着我们可以应用 jax.vmap 函数转换并立即获得损失函数渐变的版本,该版本适用于小批量示例。
jax.vmap 还可接受其他参数:
in_axes 是一个元组或整数,它告诉 JAX 函数参数应该对哪些轴并行化。元组应该与 vmap’d 函数的参数数量相同,或者只有一个参数时为整数。示例中,我们将使用(None,0,0),指“不在第一个参数(params)上并行化,并在第二个和第三个参数(x 和 y)的第一个(第零个)维度上并行化”。
out_axes 类似于 in_axes,除了它指定了函数输出的哪些轴并行化。我们在例子中使用 0,表示在函数唯一输出的第一个(第零个)维度上进行并行化(损失梯度)。
请注意,我们必须稍微修改一下训练代码——我们需要一次抓取一批数据而不是单个示例,并在应用它们来更新参数之前对批处理中的渐变求平均。

6 指南
这就是我们将在这个简短的教程中介绍的内容,但这实际上涵盖了大量的 JAX 知识。由于 JAX 主要是 numpy 和 Python,因此你可以利用现有知识,而不必学习基本的新框架或范例。
有关其他资源,请查看 JAX GitHub:
https://github.com/google/jax 上的 notebook 和示例目录。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论