

本文内容来自祁麟在 QCon 分享的主题《代码保护之道——混淆的艺术》,主要涉及黑产现状、通用防御架构、攻击流程和混淆理论。
黑产现状、盈利手段
黑产的现状及常用的盈利手段是什么?这里给出三个数字:第一个数字是 150 万,这是 2017 年网络安全生态峰会上评估出的黑产从业人员的人数。跟这个人数相比,目前业界顶尖公司中安全从业人员最多不过千余人,与黑产对比可谓凤毛麟角。第二个数字是千亿,这是网络安全生态峰会上评估的黑产年产值。根据 2017 年的腾讯阿里两家巨头的财报,两家公司净利润总和接近千亿元,黑产的年产值基本可以与这两家巨头公司并驾齐驱。第三个是 20%,这是根据我们之前经验评估的营销活动的资损率。举例来说比如要做一个新注册的拉新活动,投了 100 万去吸引用户,最后会发现至少有 20 万会进入到黑产的口袋里。
简单列举两个黑产的盈利场景。第一种是撞库,就是把其他平台泄露的一些用户名和密码,不停地拿到另外一些平台上去试,如果登录成功之后首先会窃取账号内的资产信息,之后会使用窃取的账号去做一些薅羊毛等相关的事情。第二种是垃圾注册,黑产要盈利必须要有海量的帐号,黑产会注册成千上万个小号来为后续的活动进行准备,这是万恶之源。但是实际上批量账号注册是成本非常高的事情,需要海量的手机号码、手机设备等等。工欲善其事必先利其器,黑产也深知这个道理。为了以最小的成本获取最大的收益,外挂应运而生。外挂具有批量化、虚拟化、自动化的能力,可以最大程度来满足黑产的需求。
为了抵御黑产,各家公司都会有自己专门的风控团队,使用各种各样的技术手段去进行对抗。这里介绍一个比较通用的架构(参见下图)。首先客户端会把采集到的数据加密后 (包括安全签名等) 通过业务 API 接口请求传安全网关,网关这里会有一些实时的策略引擎来进行风控,包括但不限于 IP 策略、环境设备、帐号属性、行为序列以及一些 AI 机器学习模型等等。风控结果会发送到后端的二次验证系统,如果发现前端的请求是非法的,就直接阻断请求或者弹出验证码等等。如果没有问题,就会真正交给业务系统,然后由业务系统来做一些相关的处理。同时,各家也会有对应的离线策略引擎,它会通过旁路数据进行无监督聚类甚或有监督的机器学习等等,生成更多的模型,辅助后端的风控。
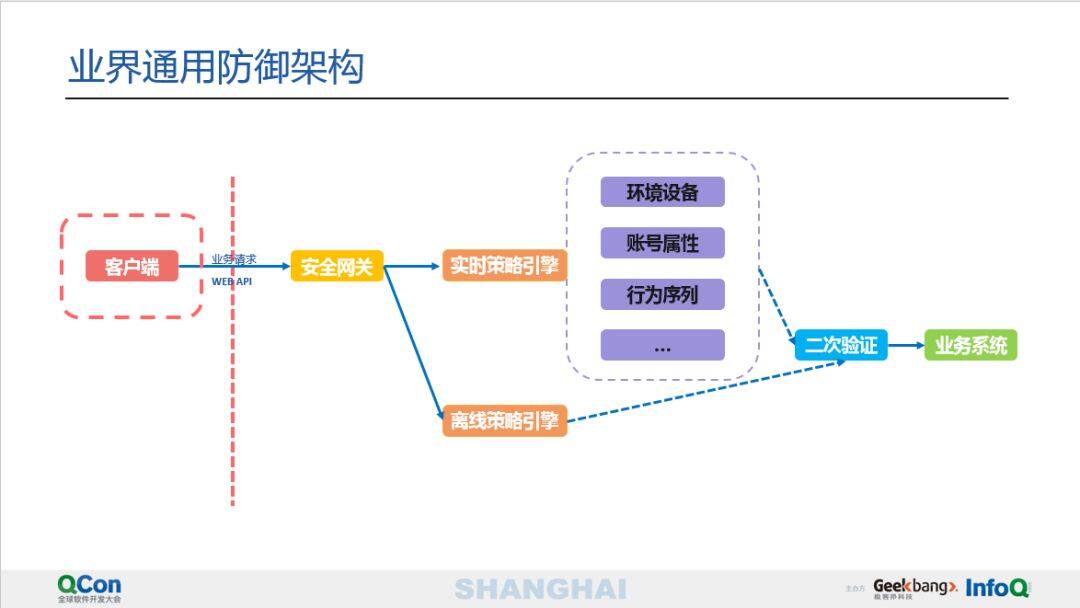
接下来重点介绍客户端保护相关的工作。整个风控系统是一个非常庞大的链路,仅就客户端而言也是一个非常复杂的体系,这里包括具体采集什么样的风控数据、如何保证采集数据的安全性和对抗的实时性等等。在移动时代,PC 时代的 WEB 的业务几乎全部都落地到了客户端,如果客户端的风控没有做好,无异于门户大开,直接给黑产提供了攻击的入口。这里介绍了基于客户端进行风控的例子,我们可以看到攻击曲线完全降低到了冰点,实际上这里并没有使用多么复杂的机器学习方法,而仅仅是基于客户端本身的混淆逻辑来实现了业务保护达到的结果。
防御方法论
第一点是天下武功唯快不破。攻防的本质实际上是成本和收益的对抗。良好的代码混淆会大大提高破解所需的时间和门槛,只要保证核心代码的更新速度快于攻击者破解的速度,就可以实现很好的保护效果。
第二点是重剑无峰,大巧不工。攻防的核心是基于可信数据的对抗,谁对系统的底层理解得更加深入,谁就在整个攻防里面掌握了主动权。同样,良好的代码混淆可以保证你的数据采集逻辑不被攻击者所知悉,这可以大大提高后端风控数据的准确性和安全性。
第三点是藏叶于林。安全是业务的天然属性,业务是安全的最佳载体。只有结合了业务的安全才是真正的安全,孤立的安全是很容易被攻击者攻破的。将业务代码和安全代码放在一起进行混淆,攻击者要破解的话,不但要摸清安全逻辑,还要了解清楚整个业务逻辑。同时,业务上的风吹草动也会为安全起到非常好的预警作用。
黑客攻击流程
在介绍完防御方法论之后,具体介绍代码混淆之前,介绍下黑客的攻击流程(参见下图)。
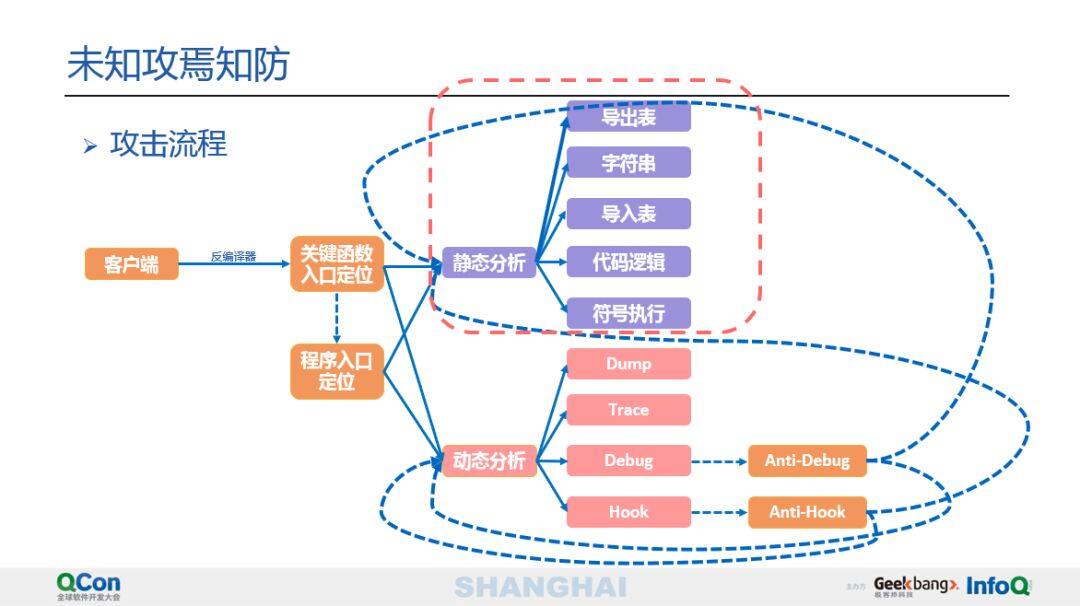
攻击的第一步是寻找入口,一般有两种方式:静态分析和动态分析。静态分析就是首先查看.so、.elf 等文件,查看其导出表。如果找不到,就看字符串表,在字符串里找信息,找到之后也可以定位到对应的位置。如果字符串表再没有,就看导入表,因为导入表里面可能会引入 MD5 等一些签名算法的值,如果导入表也没有,就得看代码逻辑了。举例来说,AES 算法有一个 S 盒,可以直接在源码中找 S 盒的特征,然后就知道这是 AES 算法,这是一个很好的线索,可以顺着该线索进而去摸清整体的逻辑。如果这些方法都行不通,还有符号执行等技术可以用来辅助分析。
动态分析首先可以利用常用的 trace 工具,如 ltrace、strace 等来分析函数的调用流,对整体流程大致有了一个了解之后需要定位到关键函数的入口,定位到关键入口之后需要结合动态调试技术,通过 GDB、LLDB 等工具利用单步调试等一些调试方法去获取信息。除此之外还有一个利器是 Hook,结合 Hook 技术将关键参数信息打印出来。同时,一些应用会采用有些客户端保护技术,如反调试、反 Hook 等。这里需要再反过来结合静态分析手段去定位安全保护的入口和代码。如果关键函数入口很难定位的话,可以定位程序入口进行分析,从程序入口机型调试来定位关键信息。总之,攻击流程就是结合上面所说的思路,利用一些安全工具或脚本来进行综合分析,最终完成对整个应用程序的逆向破解。
常用混淆理论解析
接下来介绍一些常用的混淆理论,包括有哪些常用的混淆方法,混淆的方式和其对应的效果。现代代码混淆很多是以 Collberg 理论为基础的,将代码混淆分成布局混淆、数据混淆、控制流混淆和预防混淆四大类,如下图所示。
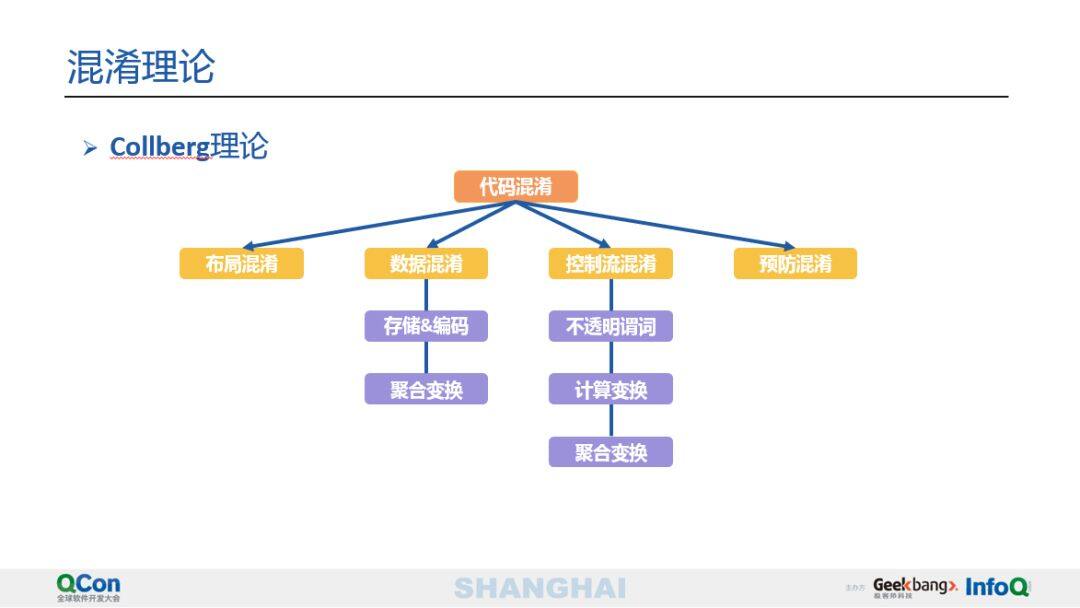
下文将继续介绍每种混淆的作用原理。
布局混淆有两个核心点:标识符重命名和删除信息。所谓标识符重命名,举例来说,就是把有意义的函数名改成无意义的函数名,隐藏函数名所传达的信息。虽然它没有本质上起到什么效果,因为逻辑没有变,但是,这减少了信息量,可以提高攻击者分析的门槛。第二个是删除信息,它包括一些调试信息、日志信息以及格式化信息等等。
标识符重命名有几种方式,第一种是标识符交换,把从 B 库里面提取的符号信息,用在 A 库里面的函数名,比如,把一个加密函数叫做解密函数。第二种是哈希命名,直接把函数变成哈希后的结果。第三个是混淆字典,这是指自己生成的一堆混淆信息,比如将 0、O 放在一起,还有 1、L 放在一起,结合起来进行函数命名,会让攻击者比较难以阅读。
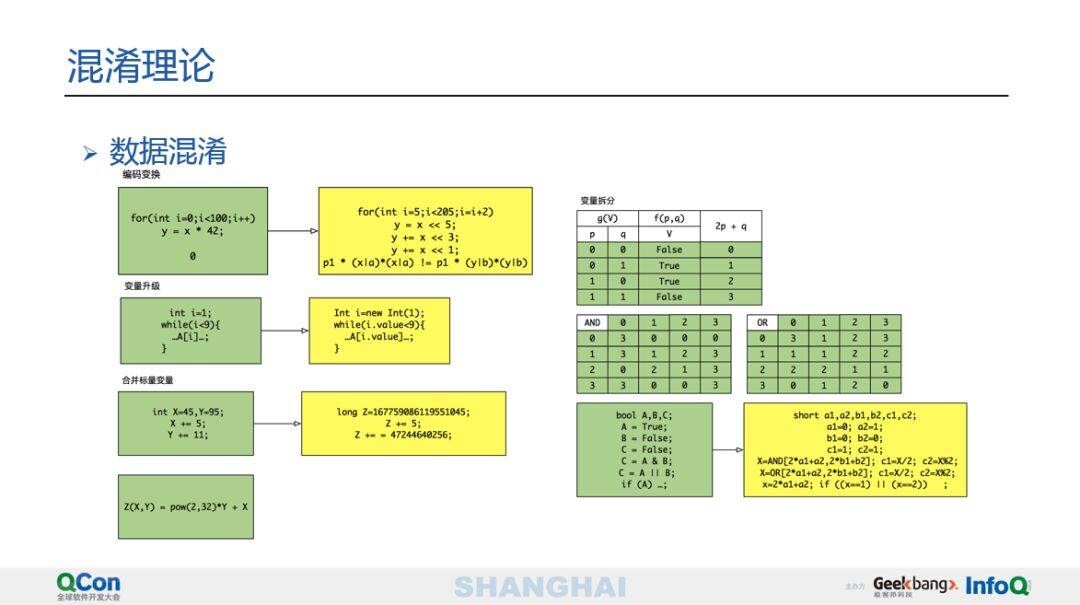
第二类是数据混淆,是针对应用程序里面的常量进行混淆,比如字符串、整型或符点数等。混淆方法包括编码变换、变量升级、拆分、数据变成函数、合并标量变量等。下图是数据混淆的一些例子。
控制流混淆是一种最核心的混淆方式,包括不透明谓词、执行混淆、聚合变换等。其中,不透明谓词是控制流混淆的核心。举例来说,有一个函数,它可能执行到 if 分支,也有可能执行到 else 分支。但是,我们可以通过某种变换让它一定走到 if 分支,而不走 else 分支。执行混淆包括虚假代码块、控制流扁平化、指令替换、控制流切割、VMProtect、代码并行化等。
第四类是预防混淆,顾名思义就是知道要逆向这个程序必须使用某个软件,我们可以针对这个软件做一些事情,比如针对反编译器插入花指令去破坏掉反编译器等等。
最后,介绍下基于 LLVM 编译器所实现的整体保护方案,因为 LLVM 的 logo 是一条龙,因此对于 LLVM 的攻坚称之为与龙共舞,我们在 LLVM 的基础上实现了深度开发。LLVM 框架的整体架构如图 5 所示,分为前端、IR 和后端,整体与标准编译原理流程完全相同。前端主要有预编译、词法分析、语法分析等流程最后生成中间向量 IR,IR 层可以进行各种各样的优化。
这里所说的代码混淆主要是在 IR 层机型实现的。IR 除了可以进行代码混淆之外,本身也是可以解释执行和基于 JIT 执行的。同时,也可以通过 inline 汇编等方式在 IR 中插入一系列的花指令。后端包括指令选择、有向无环图、指令调度、MachineIR 等,最终通过链接生成后端各种各样的架构文件。LLVM 对安全是非常有帮助的,首先可以在前端 AST 解析这里做一些安全检查,IR 可以做跨平台的代码混淆器,甚至可以在后端实现一套自己的指令集,结合自实现的编译器和解释器完成一个比较健壮的虚拟机保护方案。
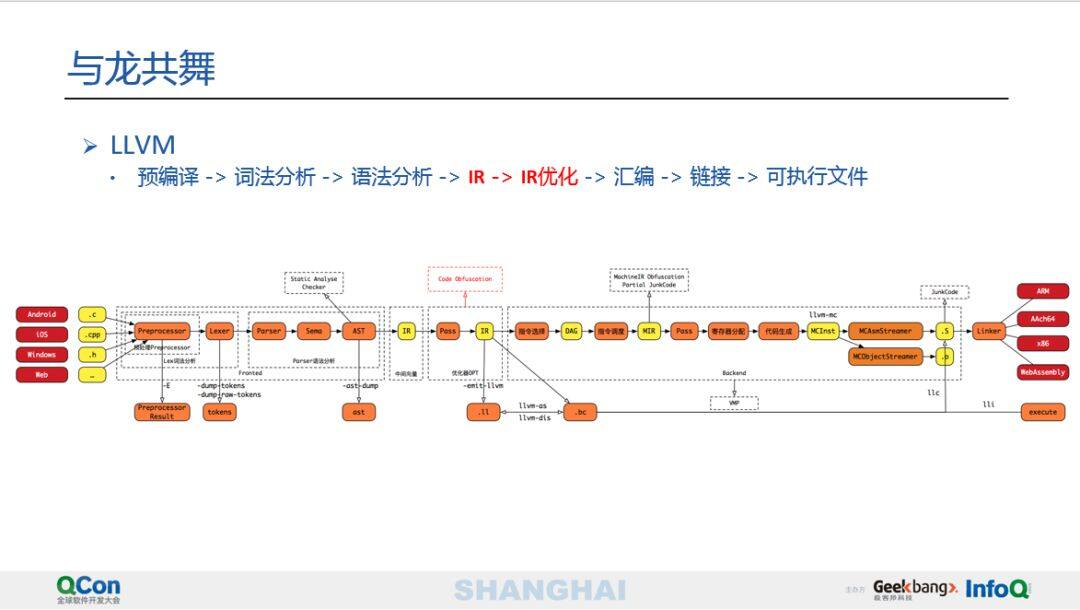
本文所讲的混淆主要是针对 IR 层实现的。它有一个好处,基本支持前端所有的语言,同时,混淆代码也基本支持后端所有的平台,实现一次代码就可以对几乎所有平台后端进行保护。同时,它是一个基于编译时的方案,所以具有很高的稳定性。LLVM IR 是基于寄存器的 SSA 格式的强类型指令集,它本身是为代码优化而设计的。LLVM 的应用非常广泛,包括安全漏洞分析、安全保护、任意函数插桩、任意代码替换、自动化测试、自动化分析等,很多自动化测试工具、安全工具等基本上都可以利用该框架来进行实现。LLVM Pass 主要对 IR 来进行操作,其结构如图所示。

实现的代码保护方案中,控制流扁平化、虚假控制流和指令替换,都借鉴了 Obfuscator-LLVM 项目。O-LLLVM 是基于编译器的代码保护方案的鼻祖,它提供了很好的思路供后续的开发者参考,但是它所开放的功能是及其有限的,并且部分实现方案存在一些弱点和 bug。因此,我们在其基础上进行了深度的定制和开发,结合混淆理论实现了更强的代码保护技术。
分享中详细阐述了字符串混淆、导入表隐藏、反调试、反篡改等基于 IR 实现的代码保护的原理和思路。
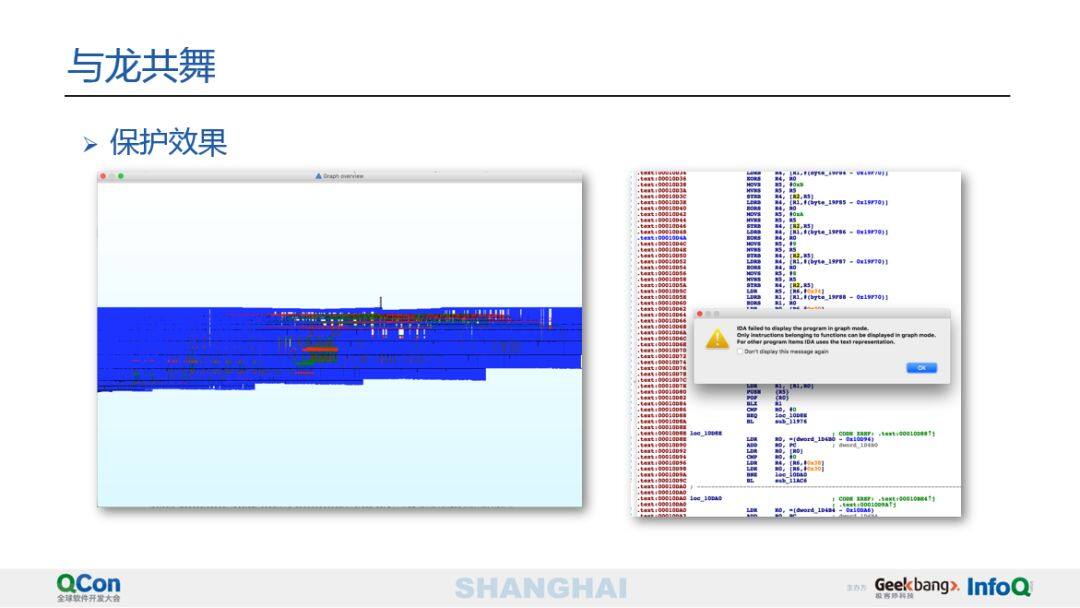
上图是实现的一些代码保护效果的例子。通过函数控制流图可以看到整体的控制流已经非常复杂了,很多攻击者到这里已经望而却步了。除此之外,结合控制流分割、花指令等技术会直接破坏了反编译器的反编译效果等等。
综上所述,结合 LLVM 框架可以实现高强度的代码混淆与保护,进而助力风控系统,有效提升整体业务安全的强度。
作者介绍:
祁麟,现就职于腾讯,任客户端高级开发工程师。2012 年加入阿里巴巴,主导并建设了阿里移动安全 SDL 标准化、自动化、流程化的安全体系,参与了阿里无线安全从 0 到 1 的全过程,并作为“阿里聚安全”的项目经理参与了阿里核心无线安全产品建设和出海全过程。2016 年加入美团负责美团移动安全防控体系的建设与团队建设。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 2 条评论